

Here at the end of Q1 2023, I’ve had a chance to look back on not just two quarters as CEO but to our decision to focus on Snowflake two years ago. And what is becoming even more crystal clear after talking to companies large and small over that time is that while they’re moving massive amounts of data to the cloud, they’re not completely moving away from existing systems. Basically, businesses have data everywhere.
We’re currently talking to a large enterprise with 17 to 20 different systems storing data: some are older legacy boxes while others are brand new micro-services. They have a lot of systems and they’re all different. What does this mean for data security? The right solution needs to support multiple and varying integration methodologies to meet data where it is and where it’s going. The end goal is for sensitive data to be classified and tokenized on ingest, travel around the business tokenized, and be de-tokenized when needed so it can be safely consumed downstream governed by logging, policy, and alerting.
And what does that mean for ALTR?
- Centralized SaaS solution: Businesses need a solution like ALTR that can be a hub or central spot from which data controls and security expand out as spokes to all the places data lives both in the cloud and on-premises. We have that with our SaaS platform and satellite Client Database Manager (CDM) on-prem components. That’s the future of data security.
- Focused on structured data: From the beginning, we focused on structured data where most of the sensitive and regulated data reside. We’ve been investing in this area from the beginning – we understand latency in a way that many other solutions don’t.
- Build on data governance and security fundamentals: Data classification and tagging, automated policy enforcement with dynamic data masking, patented rate limits and alerting, and tokenization. These are the building blocks of data security we excel at.
- Expand control and security via a library of integrations: We’ve done an excellent job of this already with our database drivers, network proxies and open-source integrations, but we need to do expand further into other data repositories like S3, Hadoop, Databricks – all the places data proliferates.
Snowflake vs Databricks
Yes, that’s a clickbait subhead. As I said, we’ve been extremely focused on Snowflake since February 2021 when we announced availability of the market’s first native cloud platform delivering observability, governance, and protection of sensitive data on Snowflake. But the truth is that a number of businesses have a use for both Snowflake and Databricks and so far, they’ve really served two different purposes:
- Databricks has traditionally been very data science focused, allowing data scientists to share their work, especially code blocks, very easily.
- Snowflake made its name by being very analytics-focused, allowing data users to load as much data as they want and share deep insights via analytics and dashboards. However, Snowflake is expanding into other data solution areas with tools such as Snowpark which enable data science workloads and applications.
Because the work use cases are primarily different as of now, the use cases for data governance and security are different as well.
In Snowflake, we see a focus on masking sensitive data and role-based access controls to keep it from users who don’t need the full information – like a data analyst using Snowflake or a Tableau report who can do what they need to with masked email addresses or masked phone numbers.
On Databricks, data scientists need full access to plain text production data so they can fully understand the distribution of the data. This means the focus is more about privacy protection and breach prevention. We see data scientists create multiple copies of the exact same data set with a light format variation. The model may produce slightly different results from the same data. That makes data governance and security more complicated because you’re basically playing cat and mouse with data constantly being copied, moved and shared – without oversight. So, we expect the solution will be focused on sensitive data discovery and classification, then automatic access logging and reporting – a kind of “overwatch” mode with tokenization underlying all of it.
ALTR’s feature set can be applied to both to solve their specific governance needs. Because we have that SaaS hub, we can now just pull the capabilities and controls we need down to wherever policy enforcement is needed.
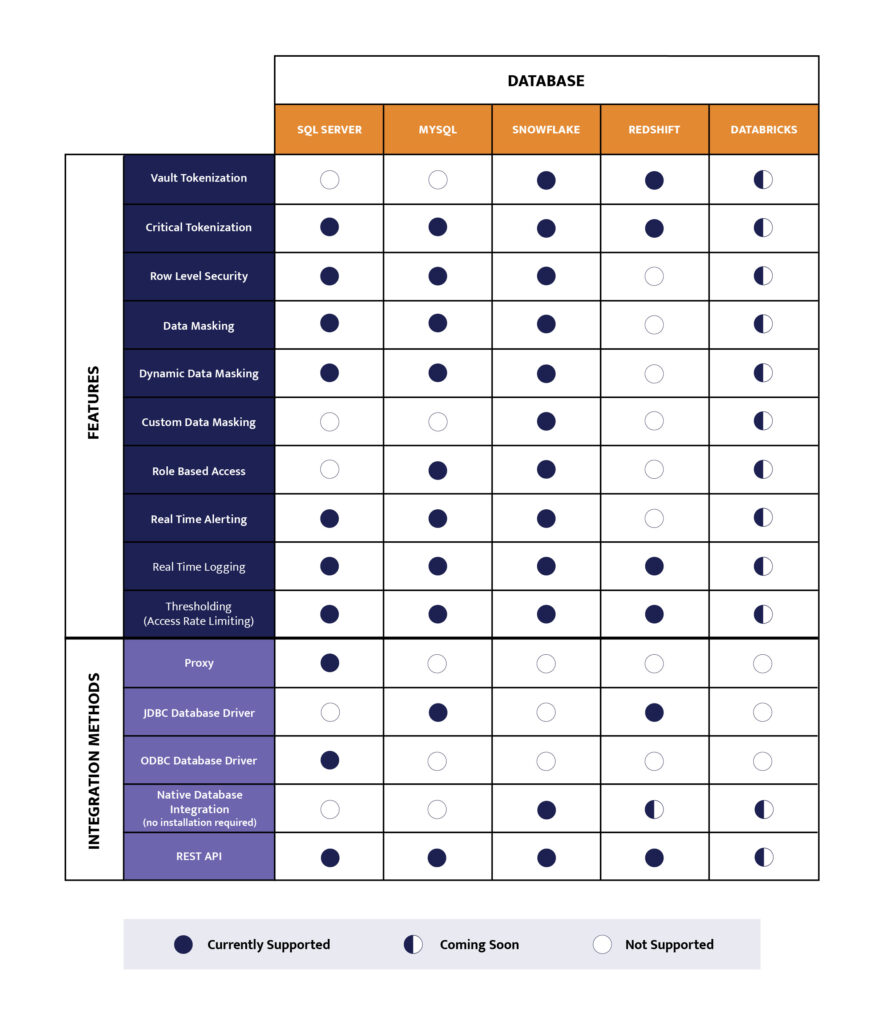
Your Single Source for Data Access Truth
So, what’s ALTR focus for the rest of this year? Building out the remaining connections to all the different data sources/data stores. Because even though the data governance and security use cases might be different across different data platforms and systems, companies don’t want to add, implement and manage different vendors. No one has time for that. They’re looking for one solution to the entire data security knot – one pane of glass, one single source for data access truth.
ALTR will make this happen this year. And if you’re interested in working with us on Databricks, Amazon Redshift, BigQuery or any other database or solution integrations, get in touch with us to help drive the features we implement and roll out. We can’t wait.
Want to try ALTR today? Sign up for our Free Plan. Or get a Demo to see how ALTR’s enterprise-ready solution can handle securing your data wherever it is.