

While there are lots of rules around how data should be protected at rest to prevent theft or breaches, the real threat to data comes from letting people use it. In fact, the easiest way to make data safe is to put it in a vault and throw away the key. But that defeats the purpose of storing data in the first place: using it to gain insight. Your highest risk and highest reward come at the intersection of users and data. That’s why role-based access controls are so critical to both data usage and data security.
What is Role-Based Access Control?
Role-based access controls restrict access to sensitive data with policies associated with various roles. These roles could be job function, job level, department, region or more. Rather than setting access by individual user or tool, these roles are set up and assigned specific permissions based on what someone in that role needs to access to do their job. A marketing person may have one set of permissions while a finance team member may have another, or Admins might have higher level access than line of business users. When new users come on board or people change jobs, the only change required is what roles they’re assigned to. This makes data access easier to manage and less error prone.
3 Strategies for RBAC
While an RBAC approach makes a lot of sense, one of the biggest challenges we see our customers facing is determining the framework they should use. Should their roles be set by department? Should it be by job level? Based on what we’ve seen work at our customers, we recommend starting with understanding how volatile your company’s business environment is: specifically, how much and how often the data, the rules around it, and which users need it will change over time.
With this strategy in mind, here are three frameworks we’ve seen successfully help companies manage the data and user intersection via role-based access controls.
RBAC Case One: Your Data, Rules and Users Rarely Change – Set It and Forget It
For smaller companies in a more static industry, all three of the variables might not be very variable. For example, a regional bank might be looking at the same kinds of data consistently over time: who logged into the banking portal, how many payments went out, and how many ATM withdrawals there were, from which ATMs? Because they’re not rolling out new product lines or other drivers of new data very often, the types of data they analyze to run their business don’t change often.
And because it’s the financial services industry, the banking rules around data security and governance are rigidly structured, specific, and slow to change. It’s rare that a new regulation around the care of personal financial data rolls out in the US. Finally, in some part because of the size of the company and focused use of the data, the data users don’t change – it’s the same 5 to 10 data analysts running the same numbers daily or weekly.
In this scenario, a company can have a pretty straightforward RBAC configuration that doesn’t require advanced data classification or tagging. The company can focus on well-defined “role-to-data” relationships.
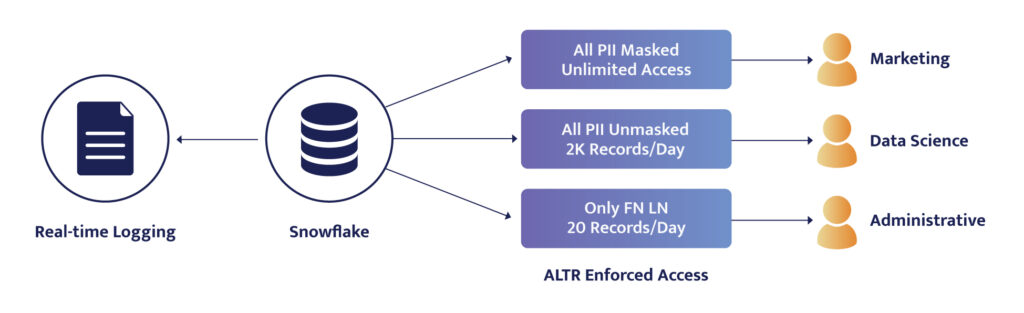
For example, all PII data could be controlled, but the way that it is masked and the amount shared is determined by the role of the person accessing it. Minimal and straightforward policies could be set for how each specific role can access data:
- Marketing role has access to all data but it’s masked
- Data scientists have access to unmasked data but only 2,000 records per day
- Administrative users could have access to unmasked data as well, but only 20 records per day
Active Directory can be integrated with Snowflake to share the role data.
RBAC Case Two: Your Data and Users Change Often but the Rules Don’t – This is Manageable
In a more dynamic industry or in a company more mature in its data lifecycle journey, there can be more variation in data and in the users needing the data, while the rules themselves don’t change much. For example, a company may be bringing in different types of data from across the company, like payroll or shipping costs. Or they might be moving into new lines of business that require different kinds of data like the most popular product color or busiest intersections. They may have a decentralized data process such that various product teams can classify, tag, and add data to the data warehouse, then request access.
In this scenario, a company can make the rules specific to the type of data and the type of access that should occur. For example, they could set up data access policies and then assign the policies appropriate to the roles:
- PII SSN – No Access
- PII SSN – Last Four
- PII SSN – Full Access
- PII Phone – No Access
- PII Phone – Last Four
- PII Phone – Full Access
A specific role could then be granted one or more of these policies. Sales may get PII Phone – Full Access + PII SSN No Access.

As data is loaded into Snowflake, it is classified in real-time and brought in with that classification such that it fits into one of these roles via how it’s tagged. Companies can then use Okta or Active Directory to assign these policies to roles.
This means that as the data changes, it’s classified in a variable way, and as the users change, whether they’re new users or existing users gaining or shedding roles and responsibilities, they’re added to new roles and policies in a variable way. The policies, however, are set just once because the rules around which kinds of data are sensitive and how it should be controlled don’t change.
This is the most scalable approach to access control.
RBAC Case Three: Everything is Changing – Try to Keep Up
Unfortunately, not every company can fit into the previous scenarios. The third situation is the most challenging: The data changes constantly, the rules change constantly, and the users change constantly. We see this more often than you might think in specific types of companies: very large enterprises acquiring new companies in new markets or moving into new locations with new regulatory environments that are all very data-driven and data-focused throughout the entire business. These enterprises must deal with a trifecta of variability: new types of data coming in, new rules based on the industry and location, and new users across the company wanting and needing access. Because they’re out in front at the leading edge, they’re all still just figuring out how to manage all these moving parts.
In this case, a user may need to switch out their role multiple times throughout the day and hence access depending on what team they’re working with and the hat they’re wearing. A data engineer, for example, might be helping the sales team with something, and then the next fire to put out is with the data science team. Their functional role might be data quality engineer, and within that function, the user may be an admin for some data sets but just a data consumer for others; for example, the user could be an account admin for marketing because they’re GDPR-certified but a read-only user for finance because they don’t have a Series 7 and can’t see customer income statements.
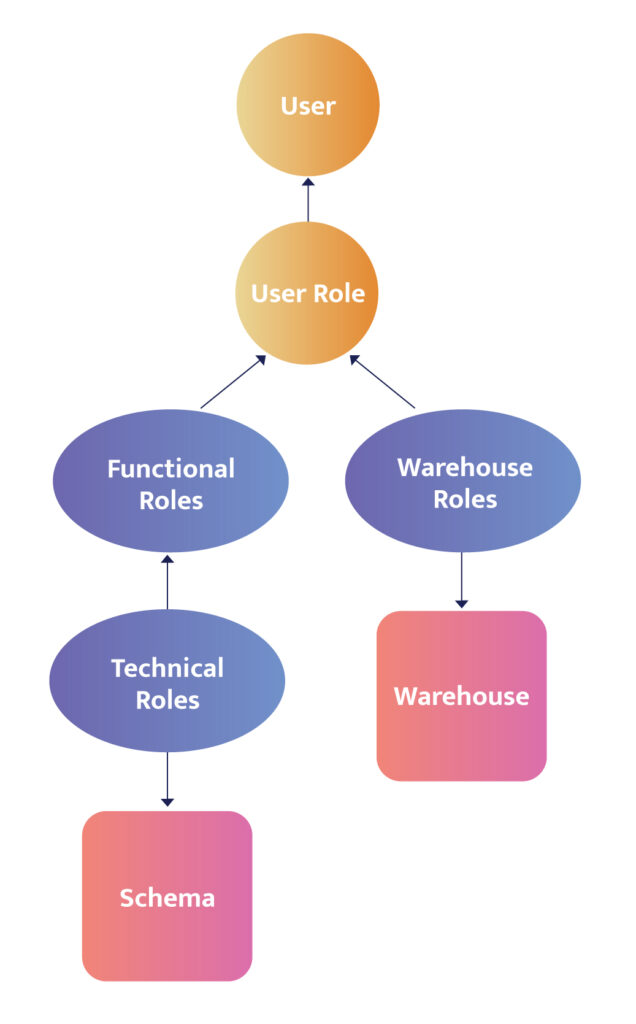
Because it’s challenging to set up static rules in this scenario, a hierarchy structure allows the RBAC to scale by placing policy over both functional roles and technical roles. Instead of making (and updating) a ridiculous number of separate roles, a data team can use that custom logic to evaluate the user when they’re running a query (what hat are they wearing when running the query?) and the classification of the data they’re trying to access. They can write about 8 or 10 lines of code that evaluates this dynamically and applies the correct access level for the role they’re playing at the time.

Role Hierarchy:
Conclusion:
The key to an effective role-based access control structure is understanding the fundamental forces affecting your data. Every business is different in the way that it consumes, stores, and processes data; in the way in which it follows regulations or defines internal policies; and in how it onboards, offboards, and categorizes its users. Those three dimensions can be unique to every organization but will generally fall into one of the above categories.
Starting from one of these as a foundation will help ensure your access controls are scalable and manageable for your business environment, and more than anything else, secure.