

What is Data Tokenization?
Tokenization is a data security technique that replaces sensitive information—such as personally identifiable information (PII), payment card numbers, or health records—with a non-sensitive placeholder called a token. The token has no exploitable value if breached, but can still be mapped back to the original data through a secure tokenization system.
By substituting tokens for live data in applications, databases, and analytics environments, organizations can reduce exposure, limit the scope of compliance requirements, and lower the risk of unauthorized access—while still enabling day-to-day operations and analysis.
How Does Tokenization of Data Work?
In a tokenization process, sensitive data is sent to a secure system that generates a surrogate value—known as a token. Tokens can be completely random or generated deterministically so that the same original value always results in the same token.
The original data is stored in a protected environment called the token vault. This vault is the only place where tokens can be mapped back to their original form. Everywhere else—in applications, reports, and data warehouses—only the token is used.
>>> You Might Also Like: Vaulted vs Vaultless Tokenization
Because there’s no mathematical link between the token and the original data, tokens can’t be reverse-engineered using conventional cryptographic attacks. The only way to retrieve the original value is by going through the tokenization system with the proper permissions and access controls.
What is Data Tokenization Used For?
Tokenization is applied wherever sensitive information needs to be protected while remaining usable for business operations. Common examples include:
- Financial data: Bank accounts, credit card numbers, and payment transactions
- Healthcare records: Patient data, diagnoses, prescriptions, and insurance details
- Government-issued IDs: Driver’s licenses, passports, and voter registrations
- Confidential business data: Loan applications, stock trades, and contract terms
In payments, tokenization is a core PCI DSS best practice. Beyond payments, organizations choose tokenization when they need:
- Regulatory alignment with strict data residency or access requirements
- Lower compliance scope by removing raw data from most systems
- Business continuity that allows analytics and reporting without exposing sensitive values
>>> You Might Also Like: 8 Signs It’s Time to Leverage Tokenization
Benefits of Data Tokenization
When it comes to cloud migration and data protection, tokenization offers the obfuscation benefits of encryption, hashing, and anonymization—while delivering much greater usability:
-
No formula or key: Tokens have no mathematical link to the original data. The real values are secured in the token vault.
-
Acts like real data: Users and applications can work with tokens as if they were live data, enabling analysis without exposing raw values.
-
Granular analytics: Tokenized data retains the ability to drill down to original details when authorized, unlike anonymized data which is locked to preset ranges.
-
Analytics plus protection: Tokenization allows advanced analytics while keeping the strong at-rest protection of encryption. Look for solutions that limit detokenization and alert on every detokenization event.
>>> You Might Also Like: Format-Preserving Encryption vs Tokenization
Three Risk-based Models for Tokenizing Data in the Cloud
Depending on the sensitivity level of your data or comfort with risk there are several spots at which you could tokenize data on its journey to the cloud. We see three main models – the best choice for your company will depend on the risks you’re facing.
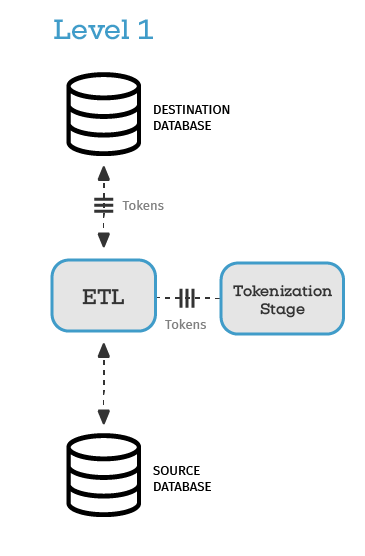
Level 1: Tokenize data before it goes into a cloud data warehouse
If you’re consolidating sensitive data from multiple databases into a single cloud data warehouse, tokenizing before ingestion protects it from both external and internal threats.
Centralizing data makes it easier for authorized users to access—but also creates a single, more attractive target for attackers, disgruntled employees, or overly privileged admins.
By tokenizing data before it’s stored in the cloud, the warehouse only holds tokens, not live values, reducing the blast radius of any breach and making compliance audits easier.
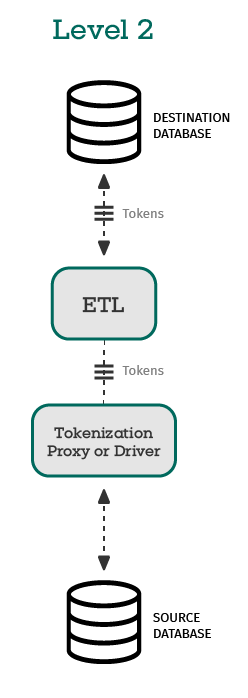
Level 2: Tokenize data before moving it through the ETL process
When sensitive data leaves your secure perimeter, especially through a third-party ETL (extract, transform, load) provider, control and visibility often diminish.
Even if you trust your vendor, contractual agreements with customers or regulations may prohibit granting them access to raw PII or regulated data without explicit consent.
Tokenizing before ETL ensures only tokens enter the pipeline, keeping the original values inside your security perimeter.
With ALTR’s integrations, this can be done seamlessly, allowing ETL tools to function normally while working only with tokens.
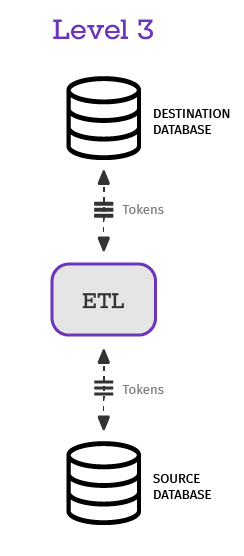
Level 3: End-to-end on-premises-to-cloud data tokenization
For organizations in highly regulated sectors such as finance or healthcare, full end-to-end tokenization is the gold standard.
This model tokenizes sensitive data at the earliest point of capture, often in on-premises databases, and maintains tokenized values all the way through to the cloud. While this approach is more complex to implement, it ensures sensitive data never exists in its original form outside of strictly controlled systems.
An added benefit: it often exposes “dark access,” hidden or unmonitored data usage, when teams discover that certain workflows no longer function without detokenization, prompting better governance.
Where ALTR Fits In
While tokenization can be implemented in many ways, ALTR delivers it as part of an integrated data security platform.
With vaulted tokenization that’s PCI Level 1–certified, ALTR offers:
- Deterministic token support so analytics work without detokenizing
- Automated classification to find and protect sensitive data quickly
- Real-time monitoring and alerting for every detokenization event
- Integration with Snowflake and other platforms for seamless adoption at scale
Whether you tokenize before the cloud, before ETL, or across the entire data journey, ALTR provides a scalable, high-performance approach that protects data without slowing down the business.
Wrapping Up
Data tokenization is one of the most effective ways to protect sensitive information while keeping it usable for the business. By removing live data from everyday systems, organizations can reduce risk, simplify compliance, and maintain operational agility.
ALTR brings this protection to life with a secure, scalable approach that integrates seamlessly into cloud and on-premises environments. Whether you need to tokenize before the cloud, before ETL, or across the entire data journey, ALTR makes it possible to safeguard data without slowing innovation.